
sito

sito

sito

sito

sito


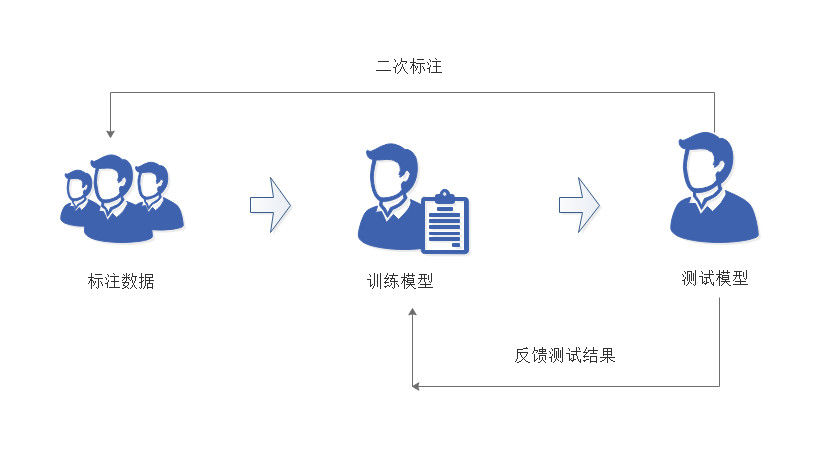
手动注释:这需要人工手动注释和审查数据。虽然这能确保高质量的输出,但却繁琐且耗时。
半自动标注:人工与 大型语言模型(LLM) 协同工作,对数据集进行标记。这既确保了人工的准确性,也增强了机器的海量数据处理能力。AI 算法可以分析原始数据并提出初步标签建议,从而节省人工标注人员的宝贵时间。(例如,AI 可以识别医学图像中潜在的感兴趣区域,以便人工进一步标记)
半监督学习:将少量标记数据与大量未标记数据相结合,以提高模型性能。
自动注释:该技术节省时间,是注释大量数据集的理想选择,它依赖于 LLM 模型固有的标记和添加属性的能力。虽然它节省时间并高效处理大量数据,但其准确性在很大程度上取决于预训练模型的质量和相关性。
指令调优:指针对自然语言指令描述的任务对语言模型进行微调,涉及对多种指令集和相应输出进行训练。
零样本学习:基于现有知识和洞察,LLM 可以将带标签的数据作为输出。这减少了获取标签的开销,非常适合处理海量数据。该技术利用模型的现有知识对尚未明确训练的任务进行预测。
提示:类似于用户向模型提示答案的方式,LLM 可以通过描述需求来注释数据。此处的输出质量直接取决于提示的质量以及输入指令的准确性。
迁移学习:在类似任务上使用预先训练的模型来减少所需的标记数据量。
主动学习:机器学习模型本身会引导数据标注过程。模型会识别对其学习最有益的数据点,并请求对这些特定点进行标注。这种有针对性的方法减少了需要标注的总体数据量,从而 提高了效率并 提升了模型性能。
 固话
固话 地址
地址 微信
微信 邮箱
邮箱 0832-2112880
0832-2112880


