
sito

sito

sito

sito

sito


默认情况下,LLM 无法理解文本和句子。它们必须经过训练才能解析每个短语和单词,从而解读用户究竟在寻找什么,并相应地提供相应的内容。LLM 微调是这一过程中的关键步骤,使这些模型能够适应特定的任务或领域。
因此,当生成式人工智能模型对查询做出最精确和最相关的响应时——即使提出最奇怪的问题——它的准确性源于它能够完美理解提示及其背后的复杂性,例如上下文、目的、讽刺、意图等。
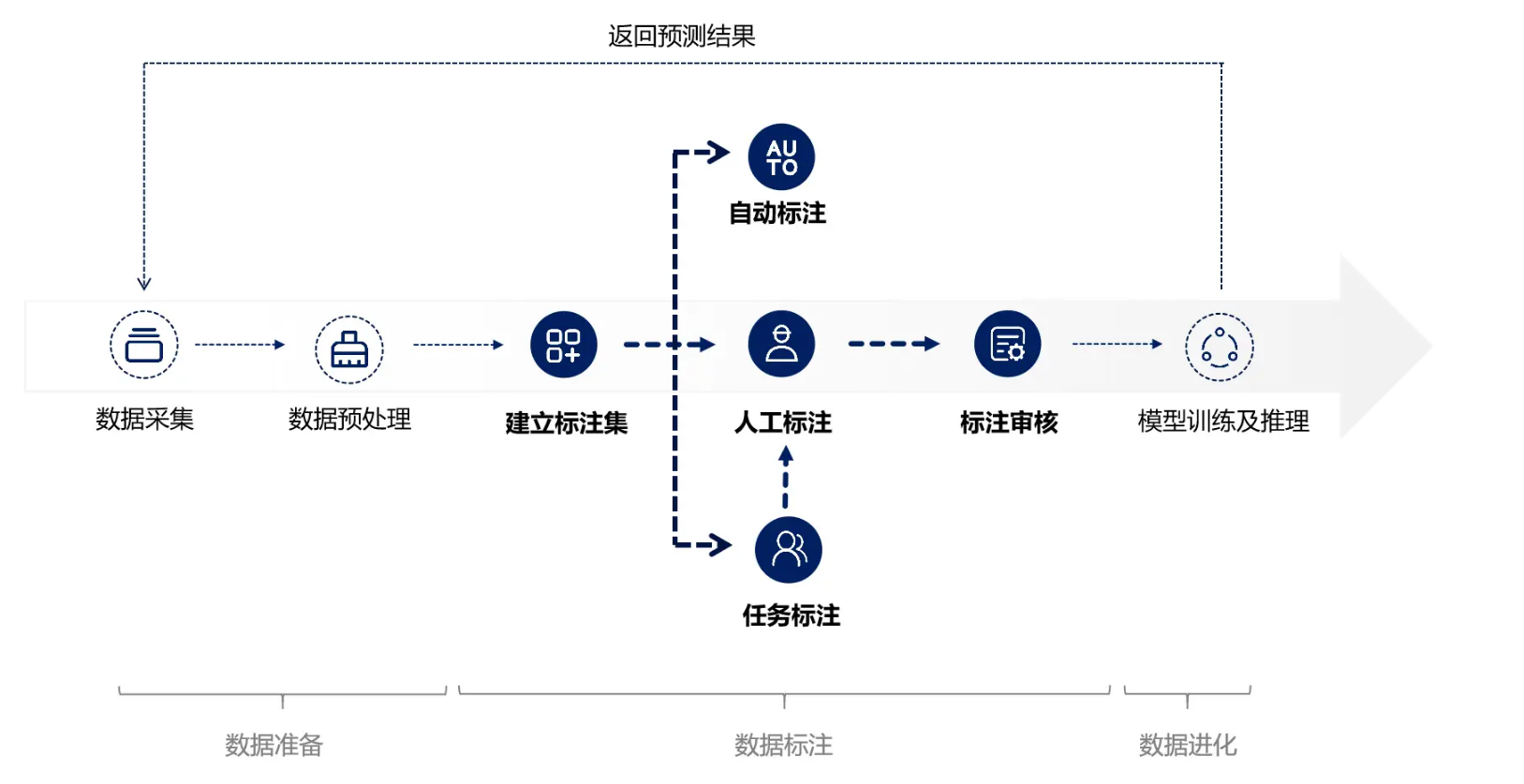
数据标注赋予 LLMS 实现这一目标的能力。 简而言之,机器学习的数据标注包括标记、分类、标注以及为数据添加任何附加属性,以便机器学习模型更好地处理和分析数据。只有通过这一关键过程,才能优化结果,使其更加完美。
在为 大型语言模型(LLM) 进行 数据标注 时,会采用多种技术。虽然没有系统的规则来指导具体实施哪种技术,但通常由专家自行决定,他们会分析每种技术的优缺点,并采用最理想的技术。默认情况下,LLM 无法理解文本和句子。它们必须经过训练才能解析每个短语和单词,从而解读用户究竟在寻找什么,并相应地提供相应的内容。LLM 微调是这一过程中的关键步骤,使这些模型能够适应特定的任务或领域。
因此,当生成式人工智能模型对查询做出最精确和最相关的响应时——即使提出最奇怪的问题——它的准确性源于它能够完美理解提示及其背后的复杂性,例如上下文、目的、讽刺、意图等。
数据标注赋予 LLMS 实现这一目标的能力。 简而言之,机器学习的数据标注包括标记、分类、标注以及为数据添加任何附加属性,以便机器学习模型更好地处理和分析数据。只有通过这一关键过程,才能优化结果,使其更加完美。
在为 大型语言模型(LLM) 进行 数据标注 时,会采用多种技术。虽然没有系统的规则来指导具体实施哪种技术,但通常由专家自行决定,他们会分析每种技术的优缺点,并采用最理想的技术。
 固话
固话 地址
地址 微信
微信 邮箱
邮箱 0832-2112880
0832-2112880


