
sito

sito

sito

sito

sito


四川数据标注的监督学习模型需要教给模型从x到y的对应关系。这有点像孩子的学习过程,如果我们想让孩子学会识别颜色,我们就需要给他们展示不同颜色的物品,并告诉他们这是什么颜色,这样孩子才能知道红色是红色,蓝色是蓝色,从而学会区分颜色。
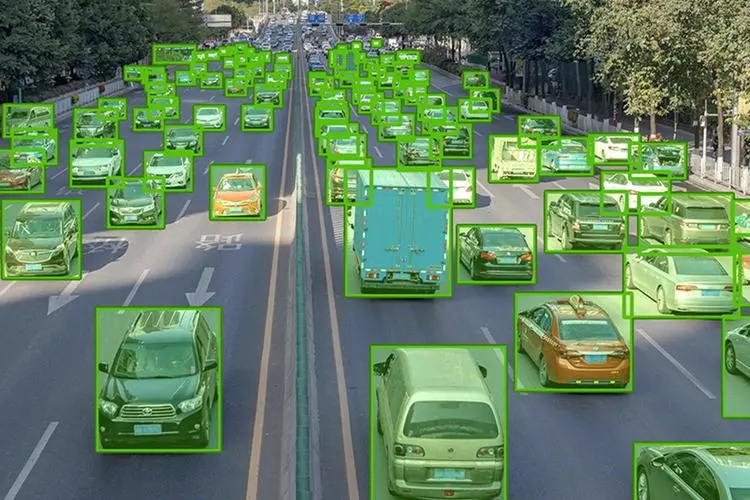
监督学习的优点是可以利用已有的标注数据来训练和评估模型,从而提高模型的准确性和可靠性。监督学习的缺点是需要大量的标注数据来支持模型的学习,这可能会增加数据标注的成本和难度,也可能会导致数据标注的错误和偏差。因此,监督学习需要有高质量和高效率的数据标注方法和工具,以保证数据标注的质量和效率。无监督学习则不需要有标注的数据,它们只需要原始数据作为输入,然后通过自己的算法来发现数据中的结构和规律。所以这种方式有点像无师自通,靠自身算法的悟性去解决问题。
例如,如果我们想让机器学习模型对一组数据进行聚类(物以类聚,人以群分),我们就不需要给数据标注任何信息,只需要让模型自己找出数据中的相似性和差异性,从而将数据分成不同的类别。
 固话
固话 地址
地址 微信
微信 邮箱
邮箱 0832-2112880
0832-2112880


